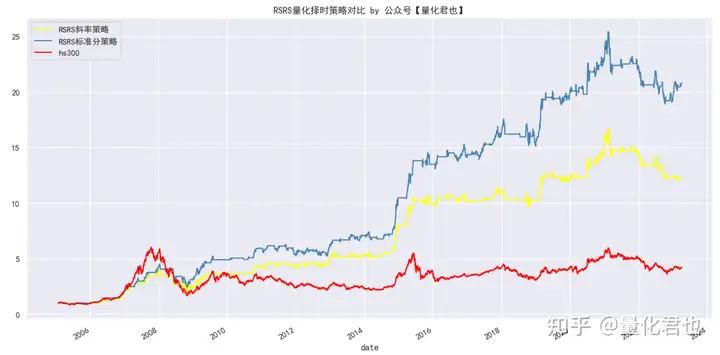
我就以复现一篇网红金融工程研究报告为例,讲述交易系统建模和量化策略研发的整个过程,从研报、数据一直唠到模型建立与回测,全程都有程序源码,以下是最终复现的效果图。
1.研报来源和指标思想
这篇网红金工研报就是光大证券在2017年劳动节发布的《基于阻力支撑相对强度的市场择时》,里面有一个网红指标RSRS,无论是做股票和ETF的,还是做期货CTA或者是大饼的圈子,都有不少人在使用,它被提及的频次仅次于MACD,说是网红指标也毫不为过。
RSRS指标的全称是“阻力支撑相对强度(Resistance Support Relative Strength)”,这个系列的研报有好几篇,目录放在文末参考资料那里了,想看的小伙伴在公Z号【量化君也】后台回复暗号『RSRS』便可以保存下载阅读。
具体的渊源和概念可以参照原版研报,如果只想听个大体思路的话,暂且听我之前的闲话唠一唠。
刚开始做交易的时候,总会听到一些”专家”预测点位,说大盘的阻力位在哪,说某只股票的支撑位在哪,各有各的理由,众说纷纭,但是预测的点位也是”一千个人眼里有一千个哈姆莱特“,不知道谁说的对。
后来慢慢发现,无论是在开发股票策略还是CTA策略,都不知不觉的使用了阻力和支撑的概念,比如说在做趋势策略之时,突破上轨做多,突破下轨做空,这个上下轨其实就类似于阻力线和支撑线,向上突破了阻力线后,广阔天地,大有可为,就开多仓,向下突破支撑线后,失去靠山,一泻千里,则开空仓或平仓。
有的时候,阻力线和支撑线并不是分开的两条线,也可以是一条线,这条线既可以是阻力线,也可以是支撑线。
就拿很多萌新入门常用的单均线策略来说,价格上穿20日均线做多,价格下穿20日均线做空,在这里,这根20日均线既是阻力线也是支撑线。价格在均线下方之时,均线便是阻力线,向上突破则做多,反之,价格在均线上方,此时均线则化身为支撑线,当价格失去支撑时则做空或平仓。
那问题来了,怎么找到阻力位和支撑位呢?听网上那些“专家”的预测吗?当然不是啦~
其实我们每天看K线图,“公认”的阻力和支撑就蕴含在里面,那就是K线的最高价和最低价,不要脸地说,这两个价格是经过万千交易者充分交易后的博弈结果,所有的成交价格都包含在了最高价和最低价形成的空间里,在最高价这条阻力线之下,在最低价这条支撑线之上。当然了,光用1天的最高价和最低价当然不行,可以用序列值。
假设我们已经有了相对靠谱的阻力位和支撑位,那应该怎么使用呢?像上下轨突破策略那样使用吗?
可以换一个思路,这就是RSRS的创新点所在,不直接使用阻力位和支撑位这种绝对阈值方式,改为使用相对强度的方式。
就好比是,绝对阈值方式就是预测清华北大的学生能否将来年入百万千万,相对强度方式则是预测清华北大的学生收入将来是否超越双非院校的学生,这两者都不是绝对事件,但两者的预测难易程度一目了然,这个比方不是很恰当,是我能想到的最好的了,只是用来说明,让大伙儿更好地体会(惶恐狗头保命状ing)。
2.RSRS斜率指标和策略
现在说清楚了阻力位和支撑位的代理变量,和指标构建的核心思想,那再来唠唠RSRS的具体计算步骤和细节。
首先,获取N日最高价和最低价的价格序列,然后,对最高价和最低价序列进行最小二乘法(OLS)线性回归,每日滚动进行,其中beta值就是斜率。
最高价 = alpha + beta×最低价
其中斜率值beta表示最高价相对最低价位置变化的程度,也就是说,当最低价变化为1的时候,最高价变动多少。
当斜率值beta很大时,支撑强度大于阻力强度,从图形上看就是,最高价的变动速度比最低价的要快,阻力逐渐减小,上涨空间大。
当斜率值beta很小时,阻力强度大于支撑强度,从图形上看就是,最高价的变动速度比最低价的要慢,上涨逐渐减缓,势头受阻见顶。
最后,这个斜率值beta就会被作为当日的RSRS值,确切来说应该是“RSRS斜率指标值”,因为后文会对指标不断改进,RSRS的含义会更加多样丰富。
RSRS的计算步骤和流程说完了,光说不练假把式,咱撸起袖子开干吧,从数据获取、指标计算和策略构建全部用代码实现和展示。
第一步,对照原版研报,获取沪深300指数从2005年至今的开高低收行情数据,这里使用的是股票量化开源库qstock,“pip install qstock”安装后,基本的功能无需注册便可以使用,萌新使用起来也非常丝滑。
import qstock as qs
# 获取沪深300指数从2005年至今的高开低收等行情数据,index是日期
data = qs.get_data(code_list=[HS300], start=20050101, freq=d)[[open,high,low,close]]
# 删除名称列、排序并去除空值
data = data.sort_index().fillna(method=ffill).dropna()
# 插入日期列
data.insert(0, date, data.index)
# 将日期从datetime格式转换为str格式
data[date] = data[date].apply(lambda x: x.strftime(%Y-%m-%d))
# 按收盘价计算每日涨幅
data[pct] = data[close] / data[close].shift(1) – 1.0
data = data.dropna().reset_index(drop=True)
print(data.head(5))
print(data.tail(5))
第二步,这里的关键是计算每一日的斜率值beta,这里先给量化萌新说一个简单具体的例子,懂最小二乘法OLS的小伙伴可跳过。
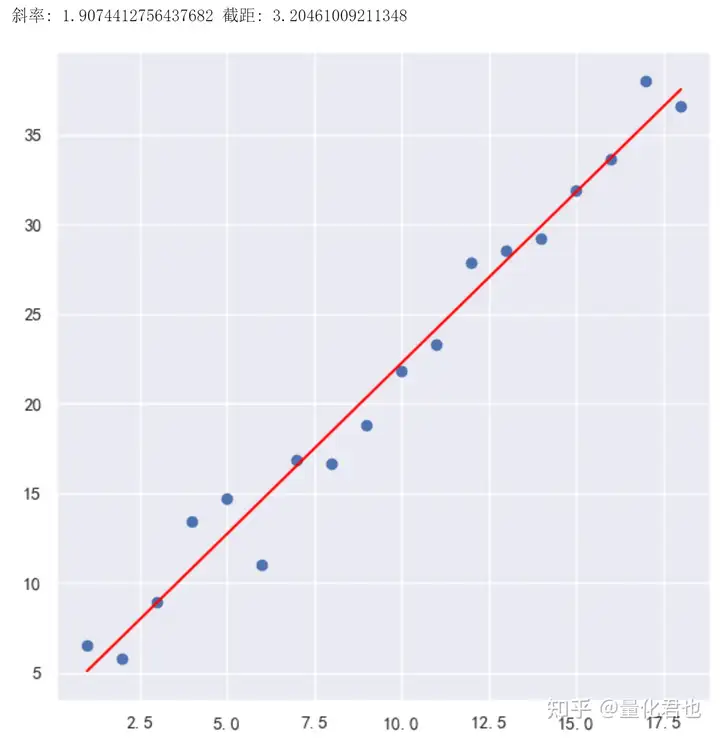
假设有18个二维的数据点,横轴X轴的坐标是1~18的等差数列,纵轴Y轴的坐标依照y=2*x_noise+1生成,x_noise是在横坐标x的基础上加入了随机数噪声,在这里,X轴数值对应的就是RSRS计算中的最低价,Y轴对应的就是最高价,具体分布如下。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
np.random.seed(0) #保证
随机数生成的一致性
N = 18 #数据点个数
x = np.arange(1, N+1)
x_noise = x + np.random.randn(N) #加入随机数噪声干扰
y = 2 * x_noise + 1
print(x:, x)
print(x_noise:, x_noise)
print(y:, y)
plt.figure(figsize=(7,7))
plt.scatter(x, y)
plt.show()
虽然有噪声的干扰,咱都知道它们的底层关系就是一条二维直线y=beta*x+alpha,其中beta=2是斜率,alpha=1是截距,最小二乘法OLS的作用就是根据已知的坐标数值,计算出斜率和截距。
在这里为了方(tou)便(lan),咱还是直接从Python免费机器学习库Scikit-learn(简称sklearn)中导入LinearRegression求解,这里要注意的是,训练集必须是二维数组(矩阵)的形式,也就是每个样本对应的是一个向量,即使这个向量只有一个数值,这里使用reshape函数快速将n维向量转换为n x 1维矩阵。从最终结果看出,解出来的斜率为1.907,跟实际值还是非常接近的。
from sklearn.linear_model import LinearRegression
lr = LinearRegression().fit(x.reshape(-1, 1), y)
y_pred = lr.predict(x.reshape(-1, 1))
beta = lr.coef_[0]
alpha = lr.intercept_
print(斜率:, beta, 截距:, alpha)
plt.figure(figsize=(7,7))
plt.scatter(x, y)
plt.plot(x, y_pred, color=red)
plt.show()
解单个序列的斜率值咱搞定了,在沪深300指数的行情数据上,咱只需要每个交易日滑动(rolling)计算18个交易日最高价vs最低价的斜率就可以了,为什么N=18呢,因为这是原版研报中在2017年定的最优参数,本期文章以复现为主,因此尊重历史客观事实按照原始参数。
def calculate_beta(df, window=18):
if df.shape[0] < window:
return np.nan
x = df[low].values
y = df[high].values
beta = LinearRegression().fit(x.reshape(-1, 1), y).coef_[0]
return beta
N = 18 #计算斜率时的数据点个数
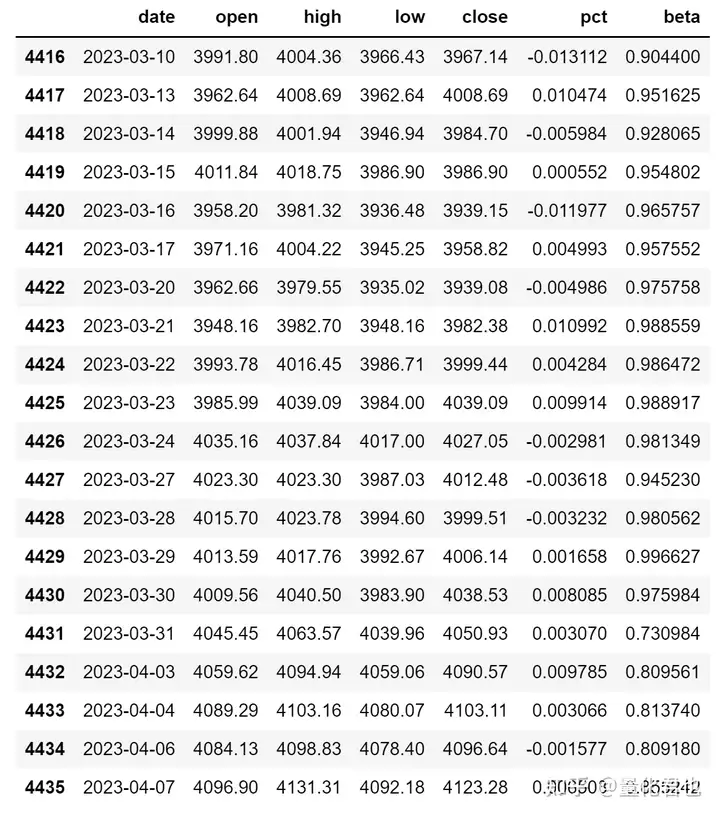
data[beta] = [calculate_beta(df,window=N) for df in data.rolling(N)]
data.tail(20)
现在咱们有了历史上每个交易日的beta值,也就是RSRS值,在这第三步里就可以构建针对大盘沪深300指数的量化择时策略了,这个策略的逻辑非常简单,就是“RSRS值大于1.0的时候,买入持有;RSRS值小于0.8,卖出平仓”,现实当中对应的交易标的可以是300ETF或IF股指期货。
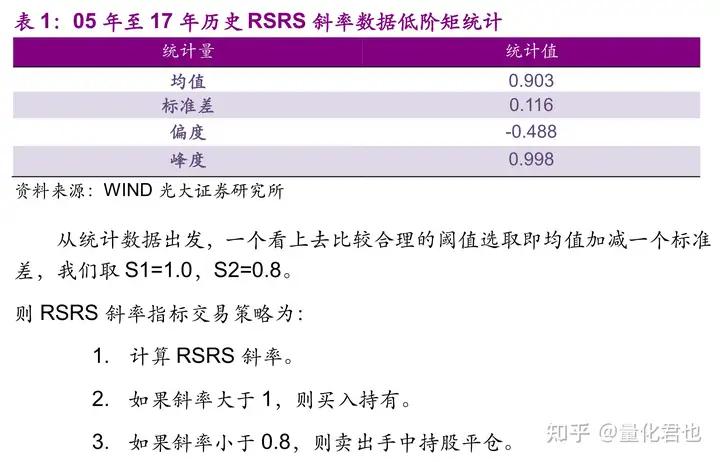
有的小伙伴可能会好奇,为什么买入阈值是1.0、卖出阈值是0.8呢?原文当中的确定方法是,根据RSRS均值加减一个标准差形成的。
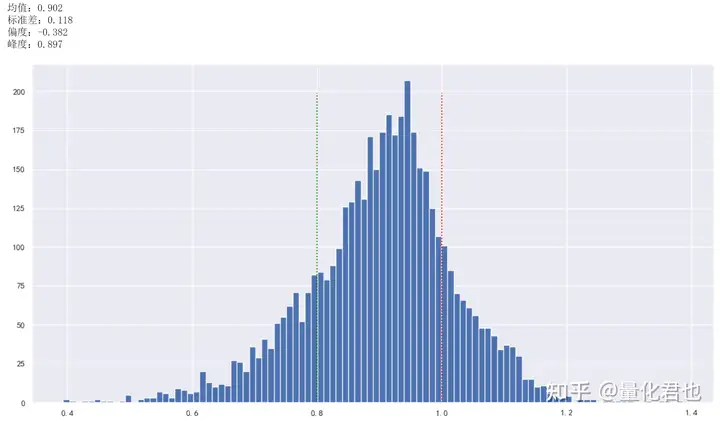
重新统计一下目前的数据,统计值和斜率分布如下,发现RSRS均值还是在0.9左右,标准差也还是在0.1左右,故买入阈值仍然可以定为1.0,卖出阈值定为0.8。
print(均值:%.3f %data[beta].mean())
print(标准差:%.3f %data[beta].std())
print(偏度:%.3f %data[beta].skew())
print(峰度:%.3f %data[beta].kurt())
y = list(range(200))
plt.figure(figsize=(16,8))
plt.hist(data[beta], bins=100)
plt.plot(len(y)*[0.8], y, color=green, linestyle=:)
plt.plot(len(y)*[1.0], y, color=red, linestyle=:)
plt.show()
买入卖出阈值确定后,RSRS值若大于1.0,买入并持有,RSRS值跌破0.8后,则卖出平仓,为了方(tou)便(lan)尊重原版研报不考虑费率影响,策略源码和回测曲线如下,总体下来比买入并一直持有基准指数要好。
buy_thre = 1.0 # 买入阈值
sell_thre = 0.8 # 卖出阈值
data1 = data.dropna().copy().reset_index(drop=True)
data1[flag] = 0 # 买卖标记,买入:1,卖出:-1
data1[position] = 0 # 持仓状态,持仓:1,不持仓:0
position = 0
for i in range(1, data1.shape[0]-1):
beta = data1.loc[i,beta]
if (position == 0) and (beta > buy_thre):
# 若之前无持仓,上穿买入阈值则买入
data1.loc[i,flag] = 1
data1.loc[i+1,position] = 1
position = 1
elif (position == 1) and (beta < sell_thre):
# 若之前有持仓,下穿卖出阈值则卖出
data1.loc[i,flag] = -1
data1.loc[i+1,position] = 0
position = 0
else:
# 不触发阈值,则保持原有持仓状态
data1.loc[i+1,position] = data1.loc[i,position]
# RSRS策略的日收益率
data1[strategy_pct] = data1[pct] * data1[position]
#策略和沪深300的净值
data1[strategy] = (1.0 + data1[strategy_pct]).cumprod()
data1[hs300] = (1.0 + data1[pct]).cumprod()
# 粗略计算
年化收益率
annual_return = 100 * (pow(data1[strategy].iloc[-1], 250/data1.shape[0]) – 1.0)
print(RSRS斜率量化择时策略的年化收益率:%.2f%% %annual_return)
#将索引从字符串转换为日期格式,方便展示
data1.index = pd.to_datetime(data1[date])
ax = data1[[strategy,hs300]].plot(figsize=(16,8), color=[SteelBlue,Red],
title=RSRS斜率量化指数择时策略净值 by 公众号【量化君也】)
plt.show()

3.RSRS标准分指标和策略
但由于市场不同时期,斜率的均值(中枢位置)会有比较大的波动,季度均值(蓝线)和年度均值(红线)如下所示,因此使用固定数值作为买入卖出阈值则不太妥当。
于是乎,研报当中提出了将原来的“RSRS斜率”转换为“RSRS标准分”,也就是在每个交易日,以M个交易日为观察期(默认M=600),将RSRS斜率做一个Z-Score标准化(即“(当前值-均值)/标准差”),便可以得到RSRS标准分,它能更加灵活地适应市场波动带来的斜率均值的变化。
有了RSRS标准分之后,便可以构建新策略,与之前的RSRS斜率策略类似,当RSRS标准分大于0.7时,买入并持有,当RSRS标准分小于-0.7时,则卖出平仓,策略源码和回测净值曲线如下所示。
M = 600 # 观察周期
buy_thre = 0.7 # 买入阈值
sell_thre = -0.7 # 卖出阈值
data2 = data.dropna().copy().reset_index(drop=True)
# 计算标准分,如果当前时间长度不够,则使用至少20交易日数据计算
data2[std_score] = (data2[beta] – data2[beta].rolling(M, min_periods=20).mean())/data2[beta].rolling(M, min_periods=20).std()
data2[flag] = 0 # 买卖标记,买入:1,卖出:-1
data2[position] = 0 # 持仓状态,持仓:1,不持仓:0
position = 0
for i in range(1, data2.shape[0]-1):
std_score = data2.loc[i,std_score]
if (position == 0) and (std_score > buy_thre):
# 若之前无持仓,上穿买入阈值则买入
data2.loc[i,flag] = 1
data2.loc[i+1,position] = 1
position = 1
elif (position == 1) and (std_score < sell_thre):
# 若之前有持仓,下穿卖出阈值则卖出
data2.loc[i,flag] = -1
data2.loc[i+1,position] = 0
position = 0
else:
# 不触发阈值,则保持原有持仓状态
data2.loc[i+1,position] = data2.loc[i,position]
# RSRS策略的日收益率
data2[strategy_pct] = data2[pct] * data2[position]
#策略和沪深300的净值
data2[strategy] = (1.0 + data2[strategy_pct]).cumprod()
data2[hs300] = (1.0 + data2[pct]).cumprod()
# 粗略计算年化收益率
annual_return = 100 * (pow(data2[strategy].iloc[-1], 250/data2.shape[0]) – 1.0)
print(RSRS标准分量化择时策略的年化收益率:%.2f%% %annual_return)
#将索引从字符串转换为日期格式,方便展示
data2.index = pd.to_datetime(data2[date])
ax = data2[[strategy,hs300]].plot(figsize=(16,8), color=[SteelBlue,Red],
title=RSRS标准分量化指数择时策略净值 by 公众号【量化君也】)
plt.show()
RSRS标准分策略看起来要比RSRS斜率策略要好,咱把它们和基准画在一张图上进行对比,这种优秀就更明显了。
data_merge = pd.merge(data1[[date,strategy]].rename(columns={strategy:RSRS斜率策略}),
data2[[strategy,hs300]].rename(columns={strategy:RSRS标准分策略}),
left_index=True, right_index=True, how=
inner)
data_merge.index = pd.to_datetime(data_merge[date])
ax = data_merge[[RSRS斜率策略,RSRS标准分策略,hs300]].plot(figsize=(16,8),
color=[Yellow,SteelBlue,Red], title=RSRS量化择时策略对比 by 公众号【量化君也】)
plt.show()
咱把研报中的RSRS策略对比图也找出来看看,研报中的数据是截止到2017年4月,当时RSRS斜率策略的累计净值是在10.57,RSRS标准分策略的累计净值是在13.37,无论是走势还是数值,总体上还是比较接近的,算是能复现出个大概了。
4.补充和总结
需要补充的是,原始研报中可能隐含了两处“未来函数”,第一处是买入卖出阈值的确定,文中是统计了全部数据集的数值(例如斜率值beta)分布再确定阈值的,相当于是用训练集训练模型,然后又让模型预测训练集。
第二处就是买卖时点的确定,当天出信号之后当日收盘价成交,虽然只要当日K线不出现“光头”或“光脚”,可以大概率近似实现,但与实盘情况还是有一定差距,只是回测起来非常方便。原版研报当中没有明说,仅为个人猜测和看法,因为这种方式回测结果与研报最接近。
总体来说整篇研报还是瑕不掩瑜,RSRS指标带有一定的创新性,不少小伙伴看了都觉得有启发,本次重点是在“复现”,于是也遵从了这两处设定。
到这里,基本的RSRS策略就已经复现完毕了,幸好总体结果跟原始研报还是一致的,暂时还没有翻车,希望已经给各位说清楚了,也让想要实现的小伙伴们少走一些弯路,节省一些精力。如果对你有帮助,可以点个充满鼓励的『赞』告诉我,接着把RSRS后续系列肝完。















发表回复