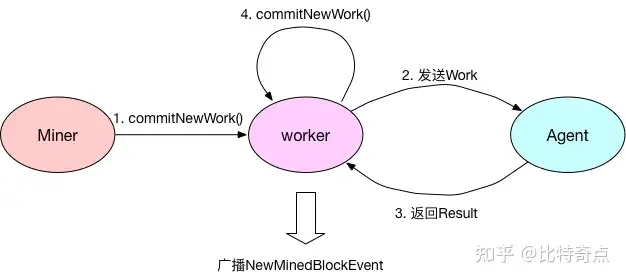
以太坊挖矿流程的基本框架参见下图:
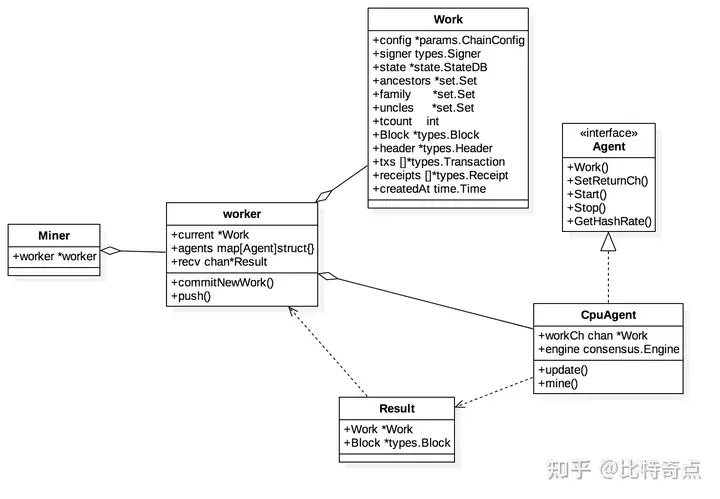
其中涉及到的组件之间的关系可以参见下面的UML图:
1. Miner启动打包
在eth Service初始化的时候,会创建一个Miner实例:
eth.miner = miner.New(eth, eth.chainConfig, eth.EventMux(), eth.engine)
我们看一下这个New()函数,代码位于miner/miner.go:
func New(eth Backend, config *params.ChainConfig, mux *event.TypeMux, engine consensus.Engine) *Miner {
miner := &Miner{
eth: eth,
mux: mux,
engine: engine,
worker: newWorker(config, engine, common.Address{}, eth, mux),
canStart: 1,
}
miner.Register(NewCpuAgent(eth.BlockChain(), engine))
go miner.update()
return miner
}
代码分为3个部分:创建Miner实例、注册Agent、等待区块同步完成,下面分别进行分析。
1.1 创建Miner实例
这一步最主要的工作是调用newWorker创建一个worker实例,Miner只是一个发起人,真正干活的是worker。看一下newWorker()函数,代码位于miner/worker.go:
func newWorker(config *params.ChainConfig, engine consensus.Engine, coinbase common.Address, eth Backend, mux *event.TypeMux) *worker {
worker := &worker{
config: config,
engine: engine,
eth: eth,
mux: mux,
txCh: make(chan core.TxPreEvent, txChanSize),
chainHeadCh: make(chan core.ChainHeadEvent, chainHeadChanSize),
chainSideCh: make(chan core.ChainSideEvent, chainSideChanSize),
chainDb: eth.ChainDb(),
recv: make(chan *Result, resultQueueSize),
chain: eth.BlockChain(),
proc: eth.BlockChain().Validator(),
possibleUncles: make(map[common.Hash]*types.Block),
coinbase: coinbase,
agents: make(map[Agent]struct{}),
unconfirmed: newUnconfirmedBlocks(eth.BlockChain(), miningLogAtDepth),
}
// Subscribe TxPreEvent for tx pool
worker.txSub = eth.TxPool().SubscribeTxPreEvent(worker.txCh)
// Subscribe events for blockchain
worker.chainHeadSub = eth.BlockChain().SubscribeChainHeadEvent(worker.chainHeadCh)
worker.chainSideSub = eth.BlockChain().SubscribeChainSideEvent(worker.chainSideCh)
go worker.update()
go worker.wait()
worker.commitNewWork()
return worker
}
这里一个比较重要的字段是recv,是一个channel类型,用于接收从Agent那边传过来的Result。
同时还启动一个goroutine运行worker.wait(),这个函数主要就是监听recv,把新区块写入数据库从而更新世界状态。
1.2 注册Agent
Agent是一个接口,定义位于miner/worker.go:
type Agent interface {
Work() chan<- *Work
SetReturnCh(chan<- *Result)
Stop()
Start()
GetHashRate() int64
}
其中Work()函数用于获取一个channel,当worker产生新的Work时会通过这个接口发送给Agent。
同时SetReturnCh()函数用于注册一个channel,当Agent这边完成POW计算后,会通过这个channel把Result发送给worker。
CpuAgent是Agent的具体实现类,可以通过NewCpuAgent()创建一个CpuAgent实例。
我们是通过调用Miner的Register()函数完成Agent注册的,参数是一个CpuAgent实例。看一下这个函数:
func (self *Miner) Register(agent Agent) {
if self.Mining() {
agent.Start()
}
self.worker.register(agent)
}
继续跟踪worker的register()函数:
func (self *worker) register(agent Agent) {
self.mu.Lock()
defer self.mu.Unlock()
self.agents[agent] = struct{}{}
agent.SetReturnCh(self.recv)
}
可以看到,这里首先在一个map中记录了这个Agent,然后调用SetReturnCh()函数注册了一个接收channel。
1.3 等待区块同步完成
在开始挖矿之前,首先需要等待和其他结点之间完成区块同步,这样才能在最新的状态挖矿。因此这里启动了一个goroutine调用Miner.update()函数:
func (self *Miner) update() {
events := self.mux.Subscribe(downloader.StartEvent{}, downloader.DoneEvent{}, downloader.FailedEvent{})
out:
for ev := range events.Chan() {
switch ev.Data.(type) {
case downloader.StartEvent:
atomic.StoreInt32(&self.canStart, 0)
if self.Mining() {
self.Stop()
atomic.StoreInt32(&self.shouldStart, 1)
log.Info(“Mining aborted due to sync”)
}
case downloader.DoneEvent, downloader.FailedEvent:
shouldStart := atomic.LoadInt32(&self.shouldStart) == 1
atomic.StoreInt32(&self.canStart, 1)
atomic.StoreInt32(&self.shouldStart, 0)
if shouldStart {
self.Start(self.coinbase)
}
// unsubscribe. were only interested in this event once
events.Unsubscribe()
// stop immediately and ignore all further pending events
break out
}
}
}
可以看到,订阅了downloader的StartEvent、DoneEvent、FailedEvent事件:
当收到StartEvent时,会把canStart置为0,这样即使你调用Miner的Start()函数也不会真正启动当收到DoneEvent或者FailedEvent时,将canStart置为1,然后调用Miner的Start()函数启动挖矿
值得注意的是,收到downloader的消息后会立即停止订阅这些消息并退出,也就是说这个函数只会运行一次。
接着看一下Miner的Start()函数:
func (self *Miner) Start(coinbase common.Address) {
atomic.StoreInt32(&self.shouldStart, 1)
self.SetEtherbase(coinbase)
if atomic.LoadInt32(&self.canStart) == 0 {
log.Info(“Network syncing, will start miner afterwards”)
return
}
atomic.StoreInt32(&self.mining, 1)
log.Info(“Starting mining operation”)
self.worker.start()
self.worker.commitNewWork()
}
可以看到这里会判断canStart标志,如果同步没有完成的话是不会真正启动的。
紧接着调用了worker的start()函数,以及最关键的commitNewWork()函数。我们先看一下start()函数:
func (self *worker) start() {
self.mu.Lock()
defer self.mu.Unlock()
atomic.StoreInt32(&self.mining, 1)
// spin up agents
for agent := range self.agents {
agent.Start()
}
}
这里会遍历所有的Agent,调用它们的Start()函数。我们可以看一下CpuAgent的Start()函数:
func (self *CpuAgent) Start() {
if !atomic.CompareAndSwapInt32(&self.isMining, 0, 1) {
return // agent already started
}
go self.update()
}
启动了一个goroutine调用update()函数,这个函数主要作用就是接收worker发送过来的Work并进行处理了,具体留待第3节分析。
2. worker打包区块,发送Work给Agent
刚刚提到了commitNewWork()是一个关键函数,完成主要的区块打包工作。这个函数比较长,分成几段来分析。
2.1 创建新区块头
parent := self.chain.CurrentBlock()
……
num := parent.Number()
header := &types.Header{
ParentHash: parent.Hash(),
Number: num.Add(num, common.Big1),
GasLimit: core.CalcGasLimit(parent),
Extra: self.extra,
Time: big.NewInt(tstamp),
}
if atomic.LoadInt32(&self.mining) == 1 {
header.Coinbase = self.coinbase
}
首先获取当前区块,然后创建一个Header结构,填充父块hash、区块高度、GasLimit、矿工地址(Coinbase)等信息。
其中GasLimit是区块中打包的交易消耗的总gas的上限,通过CalcGasLimit()函数计算出来。这个值是每生成一个区块都会动态调整的:如果上一个区块消耗的总gas < gas limit的2/3,则增大gas limit,否则减小gas limit。通过这种方式可以动态调整区块的大小。
有兴趣可以到core/block_validator.go中查阅具体代码。
2.2 初始化共识引擎
if err := self.engine.Prepare(self.chain, header); err != nil {
log.Error(“Failed to prepare header for mining”, “err”, err)
return
}
也就是调用共识引擎的Prepare()函数。默认使用基于POW算法的Ethash共识引擎,可以看一下Ethash的Prepare()函数:
func (ethash *Ethash) Prepare(chain consensus.ChainReader, header *types.Header) error {
parent := chain.GetHeader(header.ParentHash, header.Number.Uint64()-1)
if parent == nil {
return consensus.ErrUnknownAncestor
}
header.Difficulty = ethash.CalcDifficulty(chain, header.Time.Uint64(), parent)
return nil
}
首先获取父块的Header,然后根据其中的信息计算新的挖矿难度值。具体逻辑留待分析共识引擎的时候再分析。
2.3 创建新Work
err := self.makeCurrent(parent, header)
看一下makeCurrent()函数:
func (self *worker) makeCurrent(parent *types.Block, header *types.Header) error {
state, err := self.chain.StateAt(parent.Root())
if err != nil {
return err
}
work := &Work{
config: self.config,
signer: types.NewEIP155Signer(self.config.ChainId),
state: state,
ancestors: set.New(),
family: set.New(),
uncles: set.New(),
header: header,
createdAt: time.Now(),
}
// when 08 is processed ancestors contain 07 (quick block)
for _, ancestor := range self.chain.GetBlocksFromHash(parent.Hash(), 7) {
for _, uncle := range ancestor.Uncles() {
work.family.Add(uncle.Hash())
}
work.family.Add(ancestor.Hash())
work.ancestors.Add(ancestor.Hash())
}
// Keep track of transactions which return errors so they can be removed
work.tcount = 0
self.current = work
return nil
}
首先根据父块状态创建了一个新的StateDB实例。然后创建Work实例,主要初始化了它的state和header字段。
接下来还要更新Work中和叔块(Uncle Block)相关的字段。最后把新创建的Work实例赋值给self.current字段。
2.4 执行交易
work := self.current
……
pending, err := self.eth.TxPool().Pending()
if err != nil {
log.Error(“Failed to fetch pending transactions”, “err”, err)
return
}
txs := types.NewTransactionsByPriceAndNonce(self.current.signer, pending)
work.commitTransactions(self.mux, txs, self.chain, self.coinbase)
首先获取txpool的待处理交易列表的一个拷贝,然后封装进一个TransactionsByPriceAndNonce类型的结构中。这个结构中包含一个heads字段,把交易按照gas price进行排序,类型定义参见以下代码:
type TransactionsByPriceAndNonce struct {
txs map[common.Address]Transactions // Per account nonce-sorted list of transactions
heads TxByPrice // Next transaction for each unique account (price heap)
signer Signer // Signer for the set of transactions
}
接下来就是调用commitTransactions()把交易提交到EVM去执行了:
func (env *Work) commitTransactions(mux *event.TypeMux, txs *types.TransactionsByPriceAndNonce, bc *core.BlockChain, coinbase common.Address) {
gp := new(core.GasPool).AddGas(env.header.GasLimit)
……
for {
// If we dont have enough gas for any further transactions then were done
if gp.Gas() < params.TxGas {
log.Trace(“Not enough gas for further transactions”, “gp”, gp)
break
}
// Retrieve the next transaction and abort if all done
tx := txs.Peek()
if tx == nil {
break
}
……
from, _ := types.Sender(env.signer, tx)
……
// Start executing the transaction
env.state.Prepare(tx.Hash(), common.Hash{}, env.tcount)
err, logs := env.commitTransaction(tx, bc, coinbase, gp)
switch err {
……
case nil:
// Everything ok, collect the logs and shift in the next transaction from the same account
coalescedLogs = append(coalescedLogs, logs…)
env.tcount++
txs.Shift()
……
}
GasPool其实就是uint64类型,初始值为GasLimit,后面每执行一笔交易都会递减。
接下来进入循环,首先判断当前剩余的gas是否还够执行一笔交易,如果不够的话就退出循环。
然后从交易列表中取出一个,计算出发送方地址,进而提交给EVM执行。
先看一下Prepare()函数,代码位于core/state/statedb.go:
func (self *StateDB) Prepare(thash, bhash common.Hash, ti int) {
self.thash = thash
self.bhash = bhash
self.txIndex = ti
}
仅仅是几个赋值操作,记录了交易的hash,块hash目前为空,txIndex表明这是正在执行的第几笔交易。
接着看commitTransaction()函数:
func (env *Work) commitTransaction(tx *types.Transaction, bc *core.BlockChain, coinbase common.Address, gp *core.GasPool) (error, []*types.Log) {
snap := env.state.Snapshot()
receipt, _, err := core.ApplyTransaction(env.config, bc, &coinbase, gp, env.state, env.header, tx, &env.header.GasUsed, vm.Config{})
if err != nil {
env.state.RevertToSnapshot(snap)
return err, nil
}
env.txs = append(env.txs, tx)
env.receipts = append(env.receipts, receipt)
return nil, receipt.Logs
}
这里首先获取当前状态的快照,然后调用ApplyTransaction()执行交易:
如果交易执行失败,则回滚到之前的快照状态并返回错误,该账户的所有后续交易都将被跳过(txs.Pop())如果交易执行成功,则记录该交易以及交易执行的回执(receipt)并返回,然后移动到下一笔交易(txs.Shift())
2.5 处理叔块
var (
uncles []*types.Header
badUncles []common.Hash
)
for hash, uncle := range self.possibleUncles {
if len(uncles) == 2 {
break
}
if err := self.commitUncle(work, uncle.Header()); err != nil {
log.Trace(“Bad uncle found and will be removed”, “hash”, hash)
log.Trace(fmt.Sprint(uncle))
badUncles = append(badUncles, hash)
} else {
log.Debug(“Committing new uncle to block”, “hash”, hash)
uncles = append(uncles, uncle.Header())
}
}
for _, hash := range badUncles {
delete(self.possibleUncles, hash)
}
遍历所有叔块,然后调用commitUncle()把叔块header的hash添加进Work.uncles集合中。以太坊规定每个区块最多打包2个叔块的header,每打包一个叔块可以获得挖矿报酬的1/32。看一下commitUncle()函数:
func (self *worker) commitUncle(work *Work, uncle *types.Header) error {
hash := uncle.Hash()
if work.uncles.Has(hash) {
return fmt.Errorf(“uncle not unique”)
}
if !work.ancestors.Has(uncle.ParentHash) {
return fmt.Errorf(“uncles parent unknown (%x)”, uncle.ParentHash[0:4])
}
if work.family.Has(hash) {
return fmt.Errorf(“uncle already in family (%x)”, hash)
}
work.uncles.Add(uncle.Hash())
return nil
}
这里会用之前初始化的几个集合来验证叔块的有效性,以太坊规定叔块必须是之前2~7层的祖先的直接子块。如果发现叔块无效,会从集合中剔除。
2.6 打包新区块
if work.Block, err = self.engine.Finalize(self.chain, header, work.state, work.txs, uncles, work.receipts); err != nil {
log.Error(“Failed to finalize block for sealing”, “err”, err)
return
}
万事俱备,现在需要把header、txs、uncles、receipts送到共识引擎的Finalize()函数中生成新区块。
看一下Ethash的Finalize()函数:
func (ethash *Ethash) Finalize(chain consensus.ChainReader, header *types.Header, state *state.StateDB, txs []*types.Transaction, uncles []*types.Header, receipts []*types.Receipt) (*types.Block, error) {
// Accumulate any block and uncle rewards and commit the final state root
accumulateRewards(chain.Config(), state, header, uncles)
header.Root = state.IntermediateRoot(chain.Config().IsEIP158(header.Number))
// Header seems complete, assemble into a block and return
return types.NewBlock(header, txs, uncles, receipts), nil
}
这里主要做了3件事,依次开始分析。
2.6.1 计算报酬
根据以太坊的规则:
每挖出一个新区块可以获得5个以太的报酬
每包含一个叔块可以获得该块报酬的1/32
被包含的叔块对应的矿工也可以收到报酬,根据其祖先所在的层数依次递减:间隔1层,可以收到报酬的7/8间隔2层,可以收到报酬的6/8间隔3层,可以收到报酬的5/8间隔4层,可以收到报酬的4/8间隔5层,可以收到报酬的3/8间隔6层,可以收到报酬的2/8
看一下accumulateRewards(),就是按照上面的规则来实现的:
func accumulateRewards(config *params.ChainConfig, state *state.StateDB, header *types.Header, uncles []*types.Header) {
// Select the correct block reward based on chain progression
blockReward := FrontierBlockReward
if config.IsByzantium(header.Number) {
blockReward = ByzantiumBlockReward
}
// Accumulate the rewards for the miner and any included uncles
reward := new(big.Int).Set(blockReward)
r := new(big.Int)
for _, uncle := range uncles {
r.Add(uncle.Number, big8)
r.Sub(r, header.Number)
r.Mul(r, blockReward)
r.Div(r, big8)
state.AddBalance(uncle.Coinbase, r)
r.Div(blockReward, big32)
reward.Add(reward, r)
}
state.AddBalance(header.Coinbase, reward)
}
这个FrontierBlockReward定义为5e+18 wei,也就是5个以太:
FrontierBlockReward *big.Int = big.NewInt(5e+18)
2.6.2 生成MPT根
MPT全称Merkle Patricia Trie,是以太坊用来存储状态信息的一种数据结构,这棵树的根需要存储到区块头中。看一下这个IntermediateRoot()函数:
func (s *StateDB) IntermediateRoot(deleteEmptyObjects bool) common.Hash {
s.Finalise(deleteEmptyObjects)
return s.trie.Hash()
}
调用了Trie接口的Hash()方法来获取MPT的根hash,关于MPT实现的具体细节后面会专门写一篇文章分析。
2.6.3 生成新区块
最后看一下这个NewBlock()函数:
func NewBlock(header *Header, txs []*Transaction, uncles []*Header, receipts []*Receipt) *Block {
b := &Block{header: CopyHeader(header), td: new(big.Int)}
// TODO: panic if len(txs) != len(receipts)
if len(txs) == 0 {
b.header.TxHash = EmptyRootHash
} else {
b.header.TxHash = DeriveSha(Transactions(txs))
b.transactions = make(Transactions, len(txs))
copy(b.transactions, txs)
}
if len(receipts) == 0 {
b.header.ReceiptHash = EmptyRootHash
} else {
b.header.ReceiptHash = DeriveSha(Receipts(receipts))
b.header.Bloom = CreateBloom(receipts)
}
if len(uncles) == 0 {
b.header.UncleHash = EmptyUncleHash
} else {
b.header.UncleHash = CalcUncleHash(uncles)
b.uncles = make([]*Header, len(uncles))
for i := range uncles {
b.uncles[i] = CopyHeader(uncles[i])
}
}
return b
}
这里主要分为3个部分:
第1部分把所有交易组织成一个MPT,并计算它的根hash第2部分把所有回执组织成一个MPT,并计算它的根hash,另外还会创建一个bloom filter,主要是为了加快查询速度第3部分计算叔块头的hash,同时把叔块头拷贝进区块头中
2.7 向Agent推送Work
if atomic.LoadInt32(&self.mining) == 1 {
log.Info(“Commit new mining work”, “number”, work.Block.Number(), “txs”, work.tcount, “uncles”, len(uncles), “elapsed”, common.PrettyDuration(time.Since(tstart)))
self.unconfirmed.Shift(work.Block.NumberU64() – 1)
}
self.push(work)
上一步已经生成新区块了,这里会先把它放进未经确认的区块列表unconfirmed中,然后调用push()把Work推送给Agent去做POW计算:
func (self *worker) push(work *Work) {
if atomic.LoadInt32(&self.mining) != 1 {
return
}
for agent := range self.agents {
atomic.AddInt32(&self.atWork, 1)
if ch := agent.Work(); ch != nil {
ch <- work
}
}
}
可以看到,会调用Agent的Work()函数获取channel,然后把Work推送到channel中。
2.8 更新快照
self.updateSnapshot()
看一下这个updateSnapshot()函数的实现:
func (self *worker) updateSnapshot() {
self.snapshotMu.Lock()
defer self.snapshotMu.Unlock()
self.snapshotBlock = types.NewBlock(
self.current.header,
self.current.txs,
nil,
self.current.receipts,
)
self.snapshotState = self.current.state.Copy()
}
可以看到,用同样的数据创建了一个新区块,但是没有传叔块列表。创建的区块赋值给snapshotBlock字段,同时把当前的state也复制了一份作为快照。
3. Agent完成POW计算后返回Result
前面1.3节提到过,调用CpuAgent的Start()函数时,会启动一个goroutine执行update()函数,用于监听推送过来的Work。我们先看一下这个update()函数:
func (self *CpuAgent) update() {
out:
for {
select {
case work := <-self.workCh:
self.mu.Lock()
if self.quitCurrentOp != nil {
close(self.quitCurrentOp)
}
self.quitCurrentOp = make(chan struct{})
go self.mine(work, self.quitCurrentOp)
self.mu.Unlock()
case <-self.stop:
self.mu.Lock()
if self.quitCurrentOp != nil {
close(self.quitCurrentOp)
self.quitCurrentOp = nil
}
self.mu.Unlock()
break out
}
}
}
可以看到,在接收到Work后,会起一个goroutine调用mine()函数进行处理:
func (self *CpuAgent) mine(work *Work, stop <-chan struct{}) {
if result, err := self.engine.Seal(self.chain, work.Block, stop); result != nil {
log.Info(“Successfully sealed new block”, “number”, result.Number(), “hash”, result.Hash())
self.returnCh <- &Result{work, result}
} else {
if err != nil {
log.Warn(“Block sealing failed”, “err”, err)
}
self.returnCh <- nil
}
}
先调用共识引擎的Seal()函数,实际上就是进行POW计算,不断修改nonce值直到找到一个小于难度值的hash。如果计算完成,就说明成功挖出了一个新块,我们获得的返回值就是一个有效的Block。
把Work和Block组织成一个Result结构,发送给之前注册返回channel的调用者,也就是worker。
4. worker存储新区块,启动下一次打包
还记得1.1节中提到的recv字段和worker.wait()函数吗?它们就是用来接收Agent发过来的Result的。
先看一下wait()函数的基本结构:
func (self *worker) wait() {
for {
mustCommitNewWork := true
for result := range self.recv {
atomic.AddInt32(&self.atWork, -1)
if result == nil {
continue
}
block := result.Block
work := result.Work
……
}
}
是一个无限循环,从recv这个channel中读取Result,获得Work和Block。
接下来我们分段解读其他部分的代码。
4.1 修改Log中的区块hash值
for _, r := range work.receipts {
for _, l := range r.Logs {
l.BlockHash = block.Hash()
}
}
for _, log := range work.state.Logs() {
log.BlockHash = block.Hash()
}
这个Log是用来记录智能合约执行过程中产生的event的。由于之前区块尚未生成,所以无法计算区块的hash值,现在已经生成了,因此需要更新每个Log的BlockHash字段。
4.2 将区块和状态信息写入数据库
stat, err := self.chain.WriteBlockWithState(block, work.receipts, work.state)
这个WriteBlockWithState()函数的代码非常长,可以分段进行解读:
ptd := bc.GetTd(block.ParentHash(), block.NumberU64()-1)
……
currentBlock := bc.CurrentBlock()
localTd := bc.GetTd(currentBlock.Hash(), currentBlock.NumberU64())
externTd := new(big.Int).Add(block.Difficulty(), ptd)
// Irrelevant of the canonical status, write the block itself to the database
if err := bc.hc.WriteTd(block.Hash(), block.NumberU64(), externTd); err != nil {
return NonStatTy, err
}
Td即总难度(Total Difficulty),由于以太坊要求总是选择最长(总难度最大)的链作为主链,通过比较这两个值就可以知道自己挖出来的块是有效块还是叔块。这里计算出了链上当前的总难度localTd和新挖出来的区块所对应的总难度externTd。
batch := bc.db.NewBatch()
rawdb.WriteBlock(batch, block)
这段代码将新挖出的block写入数据库。
root, err := state.Commit(bc.chainConfig.IsEIP158(block.Number()))
if err != nil {
return NonStatTy, err
}
这段代码将新的世界状态更新到MPT中(缓存)。
triedb := bc.stateCache.TrieDB()
// If were running an archive node, always flush
if bc.cacheConfig.Disabled {
if err := triedb.Commit(root, false); err != nil {
return NonStatTy, err
}
} else {
……
}
这段代码将新的世界状态写入数据库。
rawdb.WriteReceipts(batch, block.Hash(), block.NumberU64(), receipts)
这段代码将所有交易执行的回执写入数据库。
reorg := externTd.Cmp(localTd) > 0
currentBlock = bc.CurrentBlock()
if !reorg && externTd.Cmp(localTd) == 0 {
// Split same-difficulty blocks by number, then at random
reorg = block.NumberU64() < currentBlock.NumberU64() || (block.NumberU64() == currentBlock.NumberU64() && mrand.Float64() < 0.5)
}
if reorg {
// Reorganise the chain if the parent is not the head block
if block.ParentHash() != currentBlock.Hash() {
if err := bc.reorg(currentBlock, block); err != nil {
return NonStatTy, err
}
}
// Write the positional metadata for transaction/receipt lookups and preimages
rawdb.WriteTxLookupEntries(batch, block)
rawdb.WritePreimages(batch, block.NumberU64(), state.Preimages())
status = CanonStatTy
} else {
status = SideStatTy
}
这里首先判断externTd和localTd的大小,会出现3种情况:
externTd > localTd:说明新挖出的区块是有效块,有资格作为链头externTd < localTd:说明已经有人在你之前挖出了新区块,且总难度更高,你挖出的是叔块externTd = localTd:说明已经有人在你之前挖出了新区块,且总难度和你相同。这种情况应该极少,如果出现的话,通过一个随机数来决策是否需要接受新挖出来的块作为链头
如果决定接受新挖出的区块作为链头,则需要判断当前链头是否是新区块的父块,如果不是的话需要进行重组,同时把状态设置为CanonStatTy。否则的话把状态设置为SideStatTy。
if status == CanonStatTy {
bc.insert(block)
}
bc.futureBlocks.Remove(block.Hash())
最后如果发现状态是CanonStatTy,说明新挖出的区块是有效块,插入新区块作为链头。
4.3 发送NewMinedBlockEvent事件
self.mux.Post(core.NewMinedBlockEvent{Block: block})
发送这个事件是为了把新挖出的区块广播给其他结点,事件处理代码位于eth/handler.go:
func (pm *ProtocolManager) minedBroadcastLoop() {
// automatically stops if unsubscribe
for obj := range pm.minedBlockSub.Chan() {
switch ev := obj.Data.(type) {
case core.NewMinedBlockEvent:
pm.BroadcastBlock(ev.Block, true) // First propagate block to peers
pm.BroadcastBlock(ev.Block, false) // Only then announce to the rest
}
}
}
4.4 发送ChainEvent事件
var (
events []interface{}
logs = work.state.Logs()
)
events = append(events, core.ChainEvent{Block: block, Hash: block.Hash(), Logs: logs})
if stat == core.CanonStatTy {
events = append(events, core.ChainHeadEvent{Block: block})
}
self.chain.PostChainEvents(events, logs)
搜了一下似乎只有filter订阅了这个事件,等以后遇到了再分析。
4.5 启动下一次打包
self.unconfirmed.Insert(block.NumberU64(), block.Hash())
if mustCommitNewWork {
self.commitNewWork()
}
这个比较简单,就是更新unconfirm列表,然后再次调用commitNewWork()启动下一次打包。
这样就完成了一次完整的挖矿流程,回到了原点。以Miner调用commitNewWork()开始,到最后worker再次调用commitNewWork()启动下一次打包。
智能合约开发、审计点击联系
发表回复